Shutl Architecture Evolution: Neo4j
Here at Shutl we’re big fans of Graph Databases, and Neo4j in particular. However we didn’t start out on day one using them, that came quite some time later.
Through this post I’ll try to chronicle the evolution of the Shutl platform, with particular emphasis on how we moved from our first, humble implementation to our current platform.
Our journey has seen us introduce many new technologies and tools; however the heart of our systems revolve around quote generation – the ability to generate a collection of available 1-hour delivery time-slots and prices. This was where our performance was critical, and as (bad) luck would have it, where our performance suffered the most. Neo4J helped overcome this.
Starting out
We now refer to the early days of Shutl as V1, the first versions of our codebase that have since been rewritten and redesigned into a service oriented architecture employing a range of technologies and languages to fit their purpose.
The beginnings of Shutl were a more modest codebase, written in Ruby(1.8), used Rails (2.3), and backed by a MySQL database. This was a decision that made sense at the time – we were an early stage start-up and before we started worrying about “does it scale?” we first needed to answer “does it work?”
Growing pains
We answered the first question: it was quick and dirty, but it worked. We had created a system that would connect local retailers and local couriers. When you as a customer made a booking on Shutl integrated retailers website, you could get an instant** quote for same day delivery, broken down into 1 hour time slots and then pick the most convenient time and book it.
**I say instant, but it soon became apparent that the performance of our quote generation was becoming an issue.
The process for getting a quote for delivery is as follows:
- Call the Shutl API and figure out which slots are available for delivery (taking into consideration the store’s opening hours and the availability of couriers that will cover the area from the store to your specified location)
- Call the Shutl API to generate a quote for each slot (comparing multiple available couriers, factoring in their performance, their price and customer feedback to name just a few our our data points)
The complexity of our system was only compounded with time. As we grew, so did our data; But more importantly so did the maturity of our quote generation and selection algorithms. Our system became smarter at picking the best quotes to present to users as we started to factor in more and more data. What started off as a relatively crude price comparison has since matured and grown in accuracy and complexity. MySQL just wasn’t able to keep up.
Improving our offering meant connecting more data. In the world of relational databases, this meant an exponential growth of JOINs as our data become increasingly connected, it also led to a drastic increase of incidental complexity in our code to deal with this
In V1 of Shutl, the call to get available slots would take ~2 seconds, then to actually get a quote for a given timeslot would take ~ 4 seconds. This meant that trying to generate multiple quotes/provide multiple delivery options became unfeasible and the UX suffered as a result. User’s would see 1 option at a time, and would have to request to see a quote for a different time slot.
Compare that with our current V2 offering, where we present users with a calendar full with 2 days worth of slots/quotes:
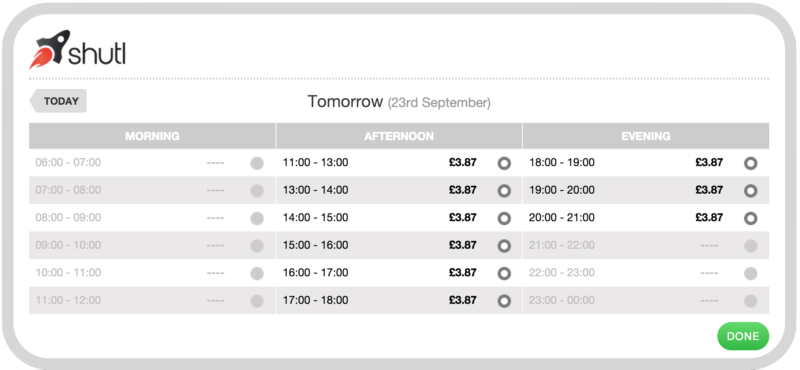
Here is how long it would have taken to generate this calendar using our V1 system.
1 call to get available slots: ~ 2 seconds
1 call to get quote for a slot: ~ 4 seconds
Assume a typical store is open for ~10 hours a day, and our calendar provides 2 days of quotes = 20 slots
total time for 1 calendar: ~ 1min 22 seconds
Exploring alternatives
The engineering team grew, both in terms of size and experience/maturity and a rewrite of V1 was planned and many things changed. It remained clear that a key consideration of this rewrite had to revolve around fixing our quote generation performance and looking at our data structures. Introducing services and improving the quality and design of our code were necessary tasks, but this alone would not improve our performance to required standards. After some exploration it became clear that graphs were a suitable option.
Why Graphs?
Domain modeling:
Our domain is a graph. This was almost a no-brainer. Delivery problems have long been used as examples for graph theory and when we started to talk about our quote generation in terms of graphs, it just fit. As an example, here’s a simplified version of a small part of our domain:
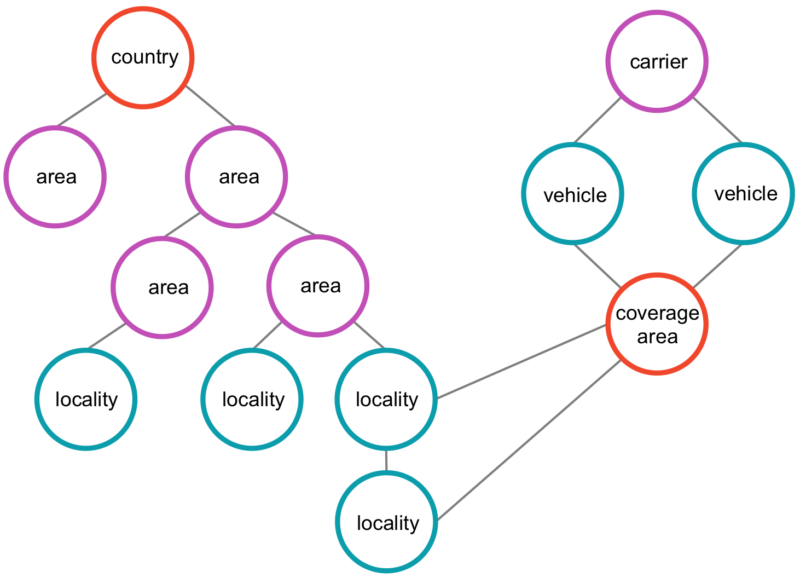
Relationships:
We struggled as our data got more connected. Relationships are a 1st class citizen in graph DBs and traversing them is significantly cheaper than performing joins via foreign keys that are traversed at query time.
Performance:
The performance of a relational database would have gotten consistently worse as the size of our data grew. Imagine introducing a new country into the domain shown above. in the relational DB world, this would directly impact queries that were for other countries, because of the increase of irrelevant data (for that specific query) in the same tables. If this was a graph, we can start our query from a specific country node, ignoring all data for other countries and therefore protecting our performance.
Why Neo4j?
The case for a graph database was strong, but Neo4J wasn’t the only option. Here’s what led us to picking neo over the competition.
Language
The majority of our systems are written in Ruby. Neo4J and Ruby work very well together and it fit with our existing skills and expertise. There were good, well maintained libraries available (we went with the neo4j gem written by Andreas Ronge).
People & Support
we met and interacted with the Neo team at various community events, they seemed like a smart bunch of people. We liked them.
Throughout our adoption the support provided has been excellent. They’ve responded fast and provided help whenever we’ve needed it. They’ve even patched and released updates based on issues we’ve faced.
Cypher
We’re fans of the Neo4J query language. It’s descriptive, easy to read and powerful. Plus it’s simple to get started with and allowed for an easy transition from SQL.
Standalone and Embedded
We had the flexibility to choose between a standalone Neo4J server that we can query via API calls or run it embedded in the JVM (which we now do, using JRuby).
The dark side of Neo
The shift wasn’t without its problems, and it’s important to be aware of the downsides and overheads when making a technology choice. Here are some of the struggles we faced:
Deployment
The consequence of choosing an embedded database in the app has deep implications in the deployment process.
Framework limitations
The lack of frameworks like ActiveRecord led to a overhead in development, for example things like validations which come built in, had to be done from scratch.
Test fixtures
We had to develop a DSL gem from scratch to help us to import various scenarios of data using the Geoff file format.
Upgrading
We are currently still stuck on Neo 1.9 as the ruby wrapper we are using doesn’t yet support 2.x
Performance
In contrast to the earlier mentions of performance, the performance of earlier versions of cypher was lacking. This led to us using less expressive transversal queries as a workaround.
Shutl reborn
The move to a graph database was absolutely the right choice for us and it’s proven its worth as more requirements have arisen over time. Take for example a recent feature we added to our systems: the ability to disable deliveries for certain time-periods by location (useful for strikes/marches and even public holidays such as Christmas). Imagine for example a planned protest march in Central London resulting in many roads being shut down. We wanted a convenient way to say “On date(s) X, we shouldn’t return any quotes for postcode(s) Y)”.
Sounds simple enough, but imagine trying to represent this in a relational database.
Now imagine trying to write the SQL query to check these conditions on every quote request. Finally, imagine the impact that would have on their performance of quote generation.
In our new Neo4J world, all we required was a simple “unavailable_on” relationship linking a “locality” to a time.
Our transition to V2 of Shutl involved a lot more than introducing Neo4J. The rewrite of V1 was accompanied by a shift in the teams’ development process, and as mentioned at the start of this post we’ve employed a number of technologies and use a variety of databases across our services to fit out needs.
Yet, quote generation remains at the core of the Shutl offering, and the core of our quote generation comes from querying the data we have in Neo4J. Ultimately, the performance for quote generation for 20 time slots went from ~82000 ms to our current performance of ~600ms, and that’s how we know we made a good decision.
2 Comments
Great article! It’s great to hear that you’re using the neo4j gem, though you might want to know that we recently came out with version 3.0.0 which actually fixes some of your issues:
– Supports the REST API (no more need for jRuby)
– ActiveRecord-like modeling (called ActiveNode and ActiveRel) uses ActiveModel/ActiveAttr for validations, etc…
– ActiveNode support ActiveRecord/arel query-chaining syntax and a low-level cypher API which lets you easily make complex cypher queries with ruby code
– Supports Neo4j 2.x
Thanks a lot for your valuable article. I will keep following your blog for more information.